Cloud Block Storage vs. Cloud Object Storage for Large-Scale Uploads
As we discussed in a previous article, standard IP technology based in TCP does not work well for large-scale uploads to cloud storage. But another piece of the cloud upload puzzle has to do with the specific nature of cloud storage.
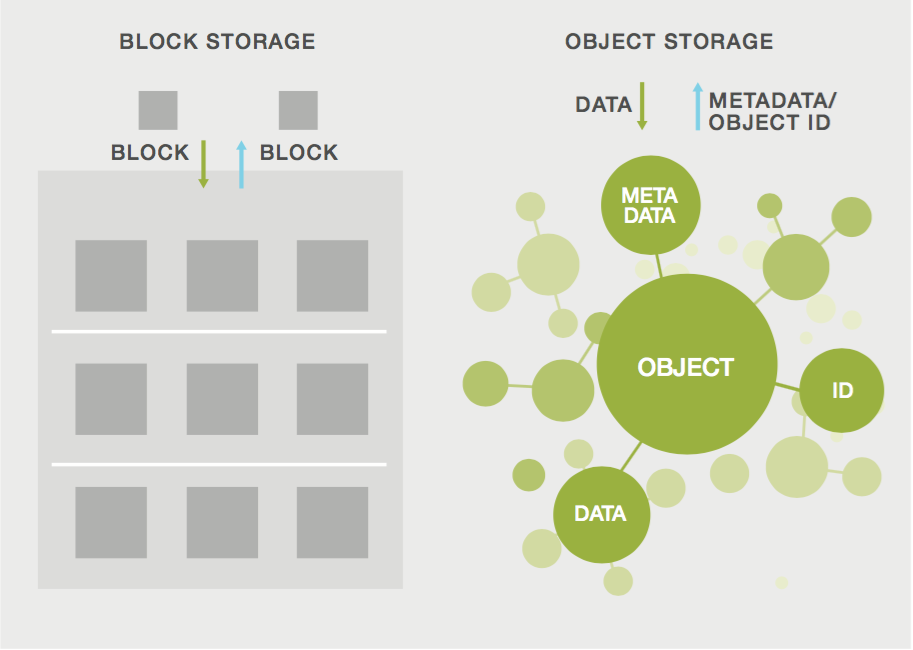
The major cloud platforms typically offer two broad classes of storage: block storage and object storage. Each type has its own product name, with tiered sub-classes available at different price/performance levels optimized for different applications.
Cloud Block Storage
Cloud block storage, such as Amazon’s AWS Elastic Block Store (EBS), in essence provides a virtualized Storage Area Network with logical volume management provisioning via a simplified web services interface.
Using a block storage offering, a logical disk drive of a given size and throughput can be connected to any cloud compute instance. This type of cloud storage can only be accessed from a cloud compute instance and only using low-layer disk access protocols.
It must be provisioned prior to use, but can be configured to support a specific number of Input/Output Operations Per Second (IOPS) to achieve specific performance objectives with software (such as databases or file systems) that interacts directly with disk drives.
Cloud Object Storage
Object storage, such as AWS S3 and Microsoft Azure Blob storage, is optimized for storing large volumes of unstructured data. Data is stored as immutable objects, the contents of which can only be written or updated in their entirety.
Object storage can be accessed directly from anywhere on the Internet using HTTP(S) protocols. Companion offerings such as AWS Glacier are targeted at archiving or ‘cold storage’ applications where very infrequent access is expected and fast access time is not critical.
Because storage provisioning is not required, object storage is highly scalable, flexible, and elastic, making it easy to adjust to demand. Object storage is the cheapest and most scalable option for data-intensive use cases such as cloud-based media processing, big data analytics, and long-term archiving and backup.
This is the application that Signiant Flight is designed for: the transfer of large data sets in and out of cloud object storage.
Moving data in and out of a cloud provider’s object storage introduces another challenge for file movement, beyond the limitations of IP networks reviewed in an earlier article.
Unlike cloud-based block storage, which can be easily mapped into a file system and is accessible using the same tools, cloud-based object storage is harder to map to a file system and requires a true integration (typically via standards-based REST and/or SOAP web services APIs) with the provider’s service layer.
Customers must utilize tools that have been integrated with their object storage provider’s APIs, an issue that Flight addresses in addition to solving the IP network bottleneck problem.